Dark Web Search Engines: The Best Onion Tools and How to Use Them

Dark web search engines are the closest thing the onion network has to Google, and the gap between that comparison and reality is the first thing to understand. There is no single index, no engine that sees the whole network, and — crucially — nothing in any result that confirms an address is genuine. Used well, these tools are a discovery layer for a network with no central directory; used carelessly, they are a fast route to a phishing clone. This guide names the engines that actually work in 2026, compares what each is good and bad at, walks through how to search onion services safely, clears up the biggest misconception about DuckDuckGo, and explains the one thing every one of these tools quietly fails to do.
How a dark web search engine actually works
An onion search engine crawls and indexes onion services so you can find them by keyword instead of memorizing 56-character addresses. That is genuinely useful, because the network has no central directory and addresses are deliberately unmemorable. But the resemblance to Google ends at the search box, and the differences are exactly what trip people up.
The first difference is coverage. There is no vast, real-time crawl of everything; these engines lean heavily on manual submissions, curated lists and user reports, so any one of them sees only a fraction of the network, and the fractions overlap unevenly. The second is freshness. Onion services appear and vanish constantly, and addresses rotate, so indexes decay fast — dead links and stale mirrors linger in results long after the real service has moved or been seized. The third, and the one that matters most, is trust. A result is a claim that an address exists, not a confirmation that it is the real one. A modern "v3" onion address is self-authenticating in a narrow sense — if it loads, you are talking to the holder of that exact cryptographic key — but the engine cannot tell you whether that key belongs to the genuine operator or to a clone that registered a near-identical address. Ranking measures relevance and popularity, never authenticity. Treat the engine as a card catalogue, not a guarantee.
The best dark web search engines, compared
A handful of engines do most of the real work, and they differ less in quality than in philosophy: some filter aggressively for safety, others index everything and leave the judgement to you. The honest framing is that there is no single best one — there is the right one for what you are doing. The table sketches the field; the notes below say what each is actually like to use.
| Engine | Indexes | Filtering | Reach | Best for |
|---|---|---|---|---|
| Ahmia | Onion services | Yes (blocks abuse) | Clearnet + Tor | A safe first stop; research, OSINT |
| Torch | Onion services | None | Tor only | Broad, unfiltered discovery |
| Haystak | Onion services | Minimal (free tier) | Clearnet + Tor | Deep search; analysts, with care |
| DuckDuckGo | The clearnet only | Standard | Clearnet + Tor | Private ordinary-web search on Tor |
| OnionLand | Onion + I2P | Minimal | Clearnet + Tor | Multi-network checks, link status |
| Not Evil | Onion services | Community-policed | Tor only | Non-commercial sites, when online |
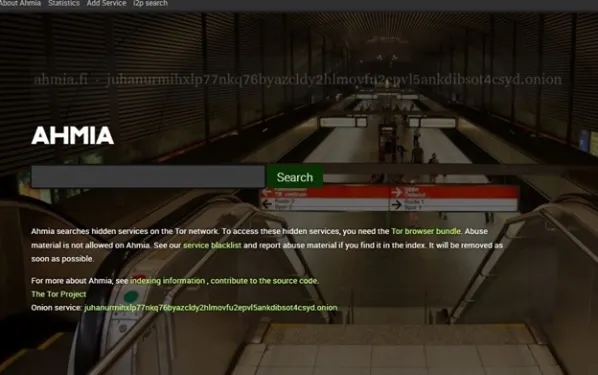
Ahmia is the one to start with. Built by security researcher Juha Nurmi and supported by the Tor Project, it is open-source, runs on the ordinary web at ahmia.fi as well as on Tor, and — alone among the popular engines — actively filters out child-abuse material and other clearly illegal content through a public blocklist. It indexes only services that allow crawling and pass that screen, so its index is smaller and cleaner. For a careful first look, nothing else is close.
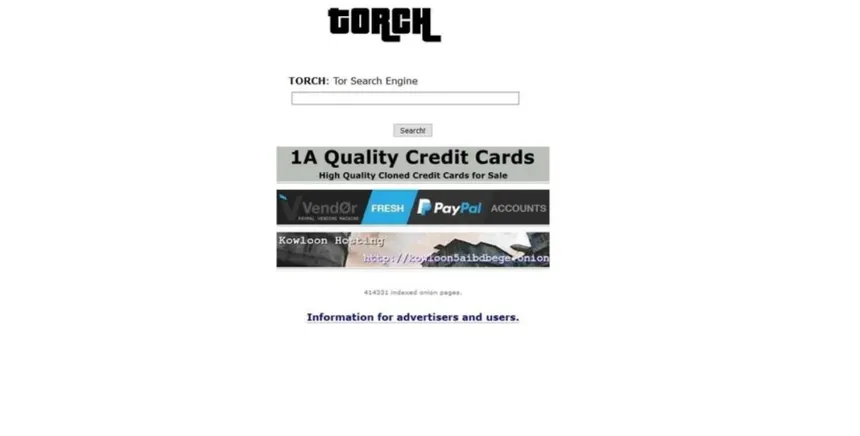
Torch is the old guard, running since the early 2010s, and it claims one of the largest indexes on the network. The trade-off is that it does no filtering at all: results are noisy with dead links, scam mirrors and ads, and it will happily surface phishing clones and worse. It is a useful net for broad discovery if you already know how to read results with suspicion, and a hazard if you do not. The banner ads on its own homepage — cloned cards, dubious "vendor" shops — are a fair preview of what it indexes.

Haystak aims for depth, claiming to have indexed well over a billion pages across hundreds of thousands of onion sites, with a free tier and a paid premium one that adds advanced filters and historical snapshots favored by analysts. Like Torch, it shows almost everything by default, so clicking through manually carries the same clone-and-malware risk; its value is reach and recall, not safety.

OnionLand spans more than one network, indexing I2P alongside Tor, which makes it handy for checking whether a known address is currently online and for cross-network discovery. Not Evil is a long-standing, community-policed engine that leans toward non-commercial services, valued when it is up — its availability has always been intermittent. A few smaller engines (Excavator, Phobos, Tor66, and others) rotate in and out of relevance; the same rules apply to all of them.
The DuckDuckGo question, answered
This is the single most common misunderstanding about searching Tor, so it is worth being blunt: DuckDuckGo does not search the dark web. It runs an official onion service and is the default search box that greets you when Tor Browser opens, which leads many people to assume it indexes .onion sites. It does not. DuckDuckGo indexes the ordinary, clearnet web — the same results you would get in any browser — and the onion address simply keeps your query inside the Tor network instead of exiting to a clearnet server. That is a real privacy benefit, and it is why the Tor Project made it the default: no tracking, no query logging, no profile.
What it means in practice is that DuckDuckGo is excellent for searching the normal web privately while you are on Tor, and useless for finding onion services. It can return a clearnet page that happens to mention an onion address — a news article, a documentation page, a directory — and that is sometimes how a real address surfaces, but it will never list a .onion site as a result or open one for you. When you actually need to find onion services, switch to a dedicated engine like Ahmia. The same caveat covers Google and Bing entirely: they do not index the dark web at all, which is the reason onion search engines had to be built in the first place.
How to search the dark web, step by step
Searching onion services is mechanically simple; the discipline around it is what keeps a search from going wrong. The short version: get on Tor properly, query a real engine, and treat every result as a lead to be checked rather than a place to trust.
- Get on Tor, configured correctly. Use the official, verified Tor Browser and raise the security level to "Safest" before you search — the full method is in our guide to accessing the dark web and our Tor Browser setup walkthrough. Searching leads to unknown pages, so this setting is doing real work.
- Go to a real engine. Start with Ahmia, which you can even open on the clearnet at ahmia.fi to preview onion results before committing. Type a keyword the way you would in any search box; you will get a list of onion services that match it.
- Copy addresses, don't reflexively click. Where you can, copy an onion address and paste it into the address bar rather than clicking a result, and read the full 56-character string before you load it. A clone differs from the real address by a couple of characters that ranking and the human eye both miss.
- Cross-check anything important. Run the same query through a second independent engine. Addresses that several engines agree on are more likely to be real; an address that only a single scam-laden directory lists is a warning, not a find.
- Verify before you trust, every time. Discovery and trust are separate steps. A result tells you an address exists; only verification tells you it is genuine. For anything touching money or identity, confirm the address against the operator's PGP-signed list using our PGP verification guide before you act on it.
Search engines vs directories like the Hidden Wiki
Alongside the crawlers sits a different kind of tool: the curated directory, of which the Hidden Wiki is the famous example. The distinction is worth keeping clear. A search engine crawls onion services automatically and lets you search by keyword; a directory is a hand-edited list you browse by category. The directory is the better choice when you do not yet know what you are looking for and want to see what kinds of services exist — and the worse choice for trust.
The Hidden Wiki has a structural problem the engines do not. There is no single, official version of it: the name is attached to dozens of mirrors and forks of wildly varying quality, many created specifically to seed phishing links, and because the lists are edited by hand, a malicious editor can swap a real market address for a clone and leave it sitting among legitimate entries. Dead links accumulate faster than anyone removes them. Visiting a Hidden Wiki page is low-risk in itself at the "Safest" level; the danger, as always, is following a link to a service that turns out to be a clone. Use a directory to orient yourself and an engine to search, but route the actual trust decision through verification — neither a category list nor a search ranking is evidence that an address is real.
Searching for a market: the dangerous part

For most people who reach this page, the real goal is narrower than "search the dark web" — it is to find a specific market. This is precisely where an onion search engine is least trustworthy and most dangerous, and saying so plainly is the most useful thing this guide can do. Markets deliberately stay out of general indexes. What an engine like Torch returns for a market's name is therefore dominated not by the genuine site but by phishing clones — pixel-perfect copies on near-identical addresses, seeded into results because users trust search rankings by habit. The engine has no way to tell the clone from the original, and neither does your eye. A result's position says nothing about whether it is real; it often says the opposite, because scammers work hardest to rank.
There is a category of tool built specifically for markets: market search engines that index vendors, listings and reviews rather than whole sites. Recon, built by the operator of the Dread forum, is the current example, indexing vendor histories across markets for due diligence; it follows Grams (which imitated Google's interface and shut down in 2017) and its successor Kilos. These can be useful for checking a vendor's track record, but they share two hard limits: they are frequently offline or unreliable, and — like every other engine — they still cannot prove that the market address you end up on is the genuine one. That proof comes from one place only. Every market in our verification directory is listed beside the operator's signed canary that confirms its address, and the closed-market record is full of users who reached a flawless-looking site they found by searching, only to discover it was a clone or a market days from draining its escrow. For a market, the search engine is the start of caution, never the end of it.
Using onion search engines without getting burned

The engines themselves are generally safe to query, and doing so is legal in most countries — running Tor and using a search engine is lawful in the United States, the UK, the EU, Canada and most of the world, and the network is used daily by journalists, researchers and people evading censorship. The danger lives in the pages the results lead to, so the safe workflow treats an engine as a lead generator and nothing more.
- Browse at "Safest." Results lead to unknown pages, and the "Safest" level disables the active content that turns a hostile page into a deanonymization attempt. It is the highest-value habit on this list.
- Never download and open files from a site you reached by search, and never enter a real-name credential on one. Most loss on this network is fraud and phishing, not exotic exploits — the careful visitor's realistic risk is being deceived, not hacked.
- Cross-check across engines. A single poisoned result is the whole attack; two independent engines agreeing on an address is the cheapest corroboration you can get, though still a lead to verify rather than a verdict.
- Keep discovery and trust separate. Use the engine to learn that a service exists and what its operator's key is, then make the trust decision with verification, never with a ranking. Collapsing the two steps is the mistake behind most of what goes wrong.
What is legal here is the searching. Specific conduct you might reach through it — buying controlled goods above all — is a separate matter governed by its own laws, and no amount of anonymity changes that. For the everyday reader, the realistic threat is a scam, and the defenses above are aimed squarely at it. For a fuller treatment of where a purchase derails, our exit-scam guide picks up where this one stops.
When the open web is the better tool
Some of the most reliable information about onion services lives on the ordinary web, not on the dark web itself, and pretending otherwise is how guides lead people astray. The Tor Project documents how onion services and their self-authenticating addresses actually work, and established security journalism tracks which markets and services are real, seized, or scams — sourced and dated in a way no onion index is. For context on what a market is and how it ends, our closed-market case studies and the dated dispatches in dark web news are more trustworthy than any ranking, because they show their evidence.
The lesson holds in 2026 as before: the best results come from combining an onion search engine for discovery with verified, off-network sources for trust. The engine tells you what exists; the open web and a signature tell you what is real. Keep those jobs separate and the search engine becomes what it should be — a useful map of a network that has no other one — rather than a false oracle about which addresses to trust.
Common questions about onion search engines
What is the best dark web search engine?
For almost everyone the answer is Ahmia, because it is the safest place to start: it is open-source, supported by the Tor Project, reachable on the ordinary web at ahmia.fi, and it filters out abuse material that the unfiltered engines leave in. Torch and Haystak index far more, but that breadth comes with scam mirrors, dead links and ads, so they suit researchers who can tell a poisoned result from a real one. "Best" depends on the job — Ahmia for a clean start, Torch or Haystak for coverage — but no engine is "best" at the thing people most want, which is confirming an address is genuine. None can do that.
Can you use DuckDuckGo to search the dark web?
No, and this is the most common misunderstanding about searching Tor. DuckDuckGo runs an onion service and is the default search box in Tor Browser, but it indexes the ordinary web, not .onion sites. Typing a query there searches the same clearnet pages you would get anywhere — it simply does so privately, over Tor. It is genuinely useful for that, and it can surface a clearnet article that mentions an onion address, but it will never return .onion sites as results. To find onion services you need a dedicated onion search engine such as Ahmia or Torch.
How do I search for .onion sites?
Open Tor Browser, raise the security level to "Safest," and go to an onion search engine — Ahmia is the easiest first stop because it also works on the clearnet at ahmia.fi. Type a keyword as you would in any search box and you will get a list of onion services that match. The important habit is what comes next: copy an address rather than clicking it where you can, cross-check anything important against a second independent engine, and treat every result as an unverified lead, not a destination you can trust on sight.
Are dark web search engines safe and legal to use?
Querying them is legal in most countries and reasonably safe in itself — running Tor and using a search engine is lawful in the United States, the UK, the EU, Canada and beyond, and the same network is used by journalists and researchers every day. The risk is not the search box; it is the pages it leads to. Results can point at phishing clones, scams or malware-serving sites, and an unfiltered engine like Torch surfaces those freely. Browse at "Safest," never download and open files, and remember that what is legal is the searching — specific conduct you might reach, such as buying controlled goods, is a separate matter governed by its own laws.
Can a search engine find a darknet market for me?
It can return something calling itself that market, which is exactly the trap. Markets deliberately stay out of general indexes, and most "market" results on an engine like Torch are phishing clones that copy the real storefront to harvest logins and coins. There are market-specific tools — Recon, and historically Grams and Kilos — that index vendors and listings, but they are frequently offline and still cannot prove an address is the genuine one. The only thing that confirms a market address is the operator's PGP signature, which is why this site routes every market through verification rather than a search result.
How is a dark web search engine different from the Hidden Wiki?
A search engine crawls onion services automatically and lets you search them by keyword; the Hidden Wiki is a hand-edited directory you browse by category. The directory is handy when you do not know what you are looking for, but it has a worse trust problem than the engines: there is no single official Hidden Wiki, dozens of clones exist specifically to seed phishing links, and editors can quietly swap a real address for a fake. Use a directory to orient yourself, an engine to search, and verification to decide what is real — none of the three is a substitute for the last.
Does Google index the dark web?
No. Google, Bing and the other mainstream engines crawl the ordinary web and do not index .onion services, which exist on the Tor network and are not reachable from a normal browser at all. That is the whole reason onion search engines exist. Google can return clearnet pages that talk about or link to onion services — including this one — but it cannot return an onion site as a result or open one for you.
How many onion search engines should I use?
More than one, because no single index is complete and cross-checking is how you catch a poisoned result. Running the same query through two or three independent engines surfaces the addresses they agree on and exposes the ones only a scam directory lists. The goal is corroboration, not coverage: two independent sources agreeing on an address is worth far more than one engine returning a hundred results — and even agreement is a lead to verify, not a guarantee.